Zenctrl
ZenCtrl 是一个综合工具包,旨在解决图像生成中的核心挑战。无需微调,可从单个主体图像生成多视角、高分辨率的图像。它能够控制形状、姿势、相机角度和上下文,非常适合进行产品摄影、时尚试穿等场景。该工具包还将发布 API,便于集成与使用。
AI设计工具AI 技术
40.8K
Xmode.ai
xMode是一个专注于AI图像训练的平台,用户可以利用其强大的算法和工具训练AI模型,快速生成高质量的图像内容。xMode的主要优点在于提供高效的训练和生成功能,背后支持先进的深度学习技术。该平台定位于为用户提供方便、快捷的AI图像训练解决方案。
图像识别
37.8K

Omniavatar
OmniAvatar 是一种先进的音频驱动视频生成模型,能够生成高质量的虚拟形象动画。其重要性在于结合了音频和视觉内容,实现高效的身体动画,适用于各种应用场景。该技术利用深度学习算法,实现高保真的动画生成,支持多种输入形式,定位于影视、游戏和社交领域。该模型是开源的,促进了技术的共享与应用。
视频生成视频动画
59.1K
Hailo AI
Hailo AI on the Edge Processors提供AI加速器和视觉处理器,支持边缘设备解决方案,旨在实现新时代的AI边缘处理和视频增强。产品定位于提供高性能深度学习应用,同时支持感知和视频增强。
AI模型边缘计算
53.0K

Bagel
BAGEL是一款可扩展的统一多模态模型,它正在革新AI与复杂系统的交互方式。该模型具有对话推理、图像生成、编辑、风格转移、导航、构图、思考等功能,通过深度学习视频和网络数据进行预训练,为生成高保真度、逼真图像提供了基础。
AI模型多模态
68.2K
国外精选

Veo 3
Veo 3 是最新的视频生成模型,旨在通过更高的现实主义和音频效果,提供 4K 输出,能更准确地遵循用户的提示。这一技术代表了视频生成领域的重大进步,具有更强的创造控制能力。Veo 3 的推出是对 Veo 2 的一次重要升级,旨在帮助创作者实现他们的创意愿景。该产品适合需要高质量视频生成的创意行业,从广告到游戏开发等多个领域。无具体价格信息披露。
视频生成深度学习
116.5K

Blip 3o
Blip 3o 是一个基于 Hugging Face 平台的应用程序,利用先进的生成模型从文本生成图像,或对现有图像进行分析和回答。该产品为用户提供了强大的图像生成和理解能力,非常适合设计师、艺术家和开发者。此技术的主要优点是其高效的图像生成速度和优质的生成效果,同时还支持多种输入形式,增强了用户体验。该产品是免费的,定位于开放给广大用户使用。
图片生成文本到图像
72.0K

MNN LLM Android App
MNN-LLM 是一款高效的推理框架,旨在优化和加速大语言模型在移动设备和本地 PC 上的部署。它通过模型量化、混合存储和硬件特定优化,解决高内存消耗和计算成本的问题。MNN-LLM 在 CPU 基准测试中表现卓越,速度显著提升,适合需要隐私保护和高效推理的用户。
模型训练与部署人工智能
62.7K

Dreamo
DreamO 是一种先进的图像定制模型,旨在提高图像生成的保真度和灵活性。该框架结合了 VAE 特征编码,适用于各种输入,特别是在角色身份的保留方面表现出色。支持消费级 GPU,具有 8 位量化和 CPU 卸载功能,适应不同硬件环境。该模型的不断更新使其在解决过度饱和和面部塑料感问题上取得了一定进展,旨在为用户提供更优质的图像生成体验。
图片生成深度学习
62.9K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型图像处理
101.6K
Primitiveanything
PrimitiveAnything 是一种利用自回归变换器生成 3D 模型的技术,能够自动创建细致的 3D 原始装配体。这项技术的主要优点在于其能通过深度学习快速生成复杂的 3D 形状,从而极大地提高了设计师的工作效率。该产品适用于各类设计应用,价格为免费使用,定位于 3D 建模领域。
3D建模深度学习
48.0K
Deerflow
DeerFlow 是一个深度研究框架,旨在结合语言模型与如网页搜索、爬虫及 Python 执行等专用工具,以推动深入研究工作。该项目源于开源社区,强调贡献回馈,具备多种灵活的功能,适合各类研究需求。
研究工具开源
65.7K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑视频处理
91.6K

Parakeet Tdt 0.6b V2
parakeet-tdt-0.6b-v2 是一个 600 百万参数的自动语音识别(ASR)模型,旨在实现高质量的英语转录,具有准确的时间戳预测和自动标点符号、大小写支持。该模型基于 FastConformer 架构,能够高效地处理长达 24 分钟的音频片段,适合开发者、研究人员和各行业应用。
语音识别深度学习
65.1K

Camerabench
CameraBench 是一个用于分析视频中相机运动的模型,旨在通过视频理解相机的运动模式。它的主要优点在于利用生成性视觉语言模型进行相机运动的原理分类和视频文本检索。通过与传统的结构从运动 (SfM) 和实时定位与*构建 (SLAM) 方法进行比较,该模型在捕捉场景语义方面显示出了显著的优势。该模型已开源,适合研究人员和开发者使用,且后续将推出更多改进版本。
研究工具相机运动
58.0K
国外精选

F Lite
F Lite 是由 Freepik 和 Fal 开发的一个大型扩散模型,具有 100 亿个参数,专门训练于版权安全和适合工作环境 (SFW) 的内容。该模型基于 Freepik 的内部数据集,包含约 8000 万张合法合规的图像,标志着公开可用的模型在这一规模上首次专注于合法和安全的内容。它的技术报告提供了详细的模型信息,并且使用了 CreativeML Open RAIL-M 许可证进行分发。该模型的设计旨在推动人工智能的开放性和可用性。
图片生成深度学习
74.2K

Kimi Audio
Kimi-Audio 是一个先进的开源音频基础模型,旨在处理多种音频处理任务,如语音识别和音频对话。该模型在超过 1300 万小时的多样化音频数据和文本数据上进行了大规模预训练,具有强大的音频推理和语言理解能力。它的主要优点包括优秀的性能和灵活性,适合研究人员和开发者进行音频相关的研究与开发。
语音识别音频处理
87.2K

Describe Anything
Describe Anything 模型(DAM)能够处理图像或视频的特定区域,并生成详细描述。它的主要优点在于可以通过简单的标记(点、框、涂鸦或掩码)来生成高质量的本地化描述,极大地提升了计算机视觉领域的图像理解能力。该模型由 NVIDIA 和多所大学联合开发,适合用于研究、开发和实际应用中。
图片生成视频处理
77.3K
国外精选

Flex.2 Preview
Flex.2 是当前最灵活的文本到图像扩散模型,具备内置的重绘和通用控制功能。它是一个开源项目,由社区支持,旨在推动人工智能的民主化。Flex.2 具备 8 亿参数,支持 512 个令牌长度输入,并符合 OSI 的 Apache 2.0 许可证。此模型可以在许多创意项目中提供强大的支持。用户可以通过反馈不断改善模型,推动技术进步。
图片生成图像生成
112.3K
Nes2net
Nes2Net 是一个为基础模型驱动的语音反欺诈任务设计的轻量级嵌套架构,具有较低的错误率,适用于音频深度假造检测。该模型在多个数据集上表现优异,预训练模型和代码已在 GitHub 上发布,便于研究人员和开发者使用。适合音频处理和安全领域,主要定位于提高语音识别和反欺诈的效率和准确性。
安全语音处理
68.7K

D1
该模型通过强化学习和高质量推理轨迹的掩蔽自监督微调,实现了对扩散大语言模型的推理能力的提升。此技术的重要性在于它能够优化模型的推理过程,减少计算成本,同时保证学习动态的稳定性。适合希望在写作和推理任务中提升效率的用户。
写作助手强化学习
69.0K
中文精选

Wan2.1 FLF2V 14B
Wan2.1-FLF2V-14B 是一个开源的大规模视频生成模型,旨在推动视频生成领域的进步。该模型在多项基准测试中表现优异,支持消费者级 GPU,能够高效生成 480P 和 720P 的视频。它在文本到视频、图像到视频等多个任务中表现出色,具有强大的视觉文本生成能力,适用于各种实际应用场景。
视频生成深度学习
81.1K

Framepack
FramePack 是一个创新的视频生成模型,旨在通过压缩输入帧的上下文来提高视频生成的质量和效率。其主要优点在于解决了视频生成中的漂移问题,通过双向采样方法保持视频质量,适合需要生成长视频的用户。该技术背景来源于对现有模型的深入研究和实验,以改进视频生成的稳定性和连贯性。
视频生成AI 技术
93.0K

Liquid
Liquid 是一个自回归生成模型,通过将图像分解为离散代码并与文本标记共享特征空间,促进视觉理解和文本生成的无缝集成。此模型的主要优点在于无需外部预训练的视觉嵌入,减少了对资源的依赖,同时通过规模法则发现了理解与生成任务之间的相互促进效应。
图片生成生成模型
84.2K
中文精选

GLM 4 32B
GLM-4-32B 是一个高性能的生成语言模型,旨在处理多种自然语言任务。它通过深度学习技术训练而成,能够生成连贯的文本和回答复杂问题。该模型适用于学术研究、商业应用和开发者,价格合理,定位精准,是自然语言处理领域的领先产品。
AI模型深度学习
95.2K

Pusa
Pusa 通过帧级噪声控制引入视频扩散建模的创新方法,能够实现高质量的视频生成,适用于多种视频生成任务(文本到视频、图像到视频等)。该模型以其卓越的运动保真度和高效的训练过程,提供了一个开源的解决方案,方便用户进行视频生成任务。
视频生成开源
95.8K

UNO
UNO 是一个基于扩散变换器的多图像条件生成模型,通过引入渐进式跨模态对齐和通用旋转位置嵌入,实现高一致性的图像生成。其主要优点在于增强了对单一或多个主题生成的可控性,适用于各种创意图像生成任务。
图片生成AI
85.3K
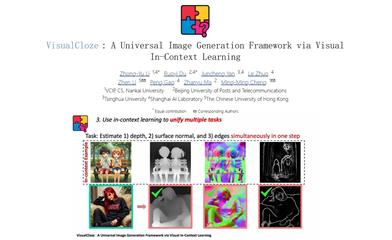
Visualcloze
VisualCloze 是一个通过视觉上下文学习的通用图像生成框架,旨在解决传统任务特定模型在多样化需求下的低效率问题。该框架不仅支持多种内部任务,还能泛化到未见过的任务,通过可视化示例帮助模型理解任务。这种方法利用了先进的图像填充模型的强生成先验,为图像生成提供了强有力的支持。
图片生成视觉学习
99.6K
Skyreels A2
SkyReels-A2 是一个基于视频扩散变换器的框架,允许用户合成和生成视频内容。该模型通过利用深度学习技术,提供了灵活的创作能力,适合多种视频生成应用,尤其是在动画和特效制作方面。该产品的优点在于其开源特性和高效的模型性能,适合研究人员和开发者使用,且目前不收取费用。
视频生成深度学习
80.0K

Megatts 3
MegaTTS 3 是由字节跳动开发的一款基于 PyTorch 的高效语音合成模型,具有超高质量的语音克隆能力。其轻量级架构只包含 0.45B 参数,支持中英文及代码切换,能够根据输入文本生成自然流畅的语音,广泛应用于学术研究和技术开发。
语音克隆深度学习
121.7K
- 1
- 2
- 3
- 4
- 5
- 6
- 10
精选AI产品推荐
中文精选

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台应用开发
163.7K
优质新品

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成AI
116.7K
国外精选

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具创意工具
135.8K
Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型图像处理
101.6K
国外精选

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要AI
67.6K
Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑视频处理
91.6K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成文本转语音
663.0K
中文精选

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型图像生成
8.0M
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文