使用场景
游戏公司使用Respeecher为新游戏中不同性别、年龄的角色配音
YouTuber使用Respeecher将自身声音转换为卡通人物的声音
配音员使用Respeecher将自己的配音转换为明星的声音
产品特色
语音转换:支持男声转女声、改变语音年龄、语言转换等
语音塑造:可对语音的音调、音色、语速等参数进行调整
语音配音:可实现人声配音,适用于影视、游戏等领域







精选AI产品推荐
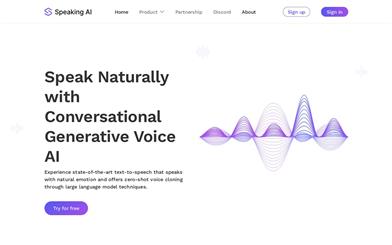
Speaking AI
Speaking AI是一款使用先进的大语言模型技术实现的文本到语音转换工具,能够以自然的情感进行对话并实现零样本语音克隆。它可以捕捉你独特的音调、音高和调节,让你以前所未有的方式复制和利用自己的声音。Speaking AI通过先进的技术实现了声音克隆的突破,让语音克隆听起来更加自然。使用Speaking AI,你可以通过录制自己的声音,在短短10秒钟内进行克隆。我们致力于将最先进的AI技术用于推动人类进步,特别是在促进语音克隆技术的发展和应用方面。
语音克隆AI
14.0M
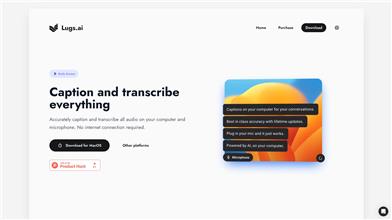
Lugs.ai
Lugs.ai是一款能够在电脑上准确实时生成字幕的插件。无需联网,支持电脑内的所有音频,包括麦克风录音和电脑上的声音。它使用AI技术,可以深度理解对话内容,并根据上下文进行准确的转写和字幕生成。Lugs.ai是由听力受损者开发的,始终以实际使用体验为依据进行不断优化。具备最佳的准确性和持续的更新。
语音识别转写
849.8K
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文