
Amazon Nova Sonic
简介 :
Amazon Nova Sonic 是一款前沿的基础模型,能够整合语音理解和生成,提升人机对话的自然流畅度。该模型克服了传统语音应用中的复杂性,通过统一的架构实现更深层次的交流理解,适用于多个行业的 AI 应用,具有重要的商业价值。随着人工智能技术的不断发展,Nova Sonic 将为客户提供更好的语音交互体验,提升服务效率。
需求人群 :
该产品特别适合开发者和企业客户,尤其是那些需要构建自然语言处理应用的团队。由于其高度的适应性和流畅的对话能力,Nova Sonic 能够有效提升客户服务体验。
使用场景
旅行助手:AI 助手根据客户的语调变化,提供个性化的旅行建议。
企业助手:AI 助手利用公司数据生成自然的业务报告,并进行互动。
在线教育:AI 教师根据学生的提问与情绪调整教学内容。
产品特色
统一语音理解和生成能力,简化开发流程。
实时根据语音输入的音调和风格调整生成的语音。
理解人类对话中的自然停顿和犹豫。
生成用户语音的文本转录,方便调用工具和 API。
支持多轮对话,无需显式设置上下文。
适用于多个行业,包括旅游、教育、医疗等。
使用教程
访问 Amazon Bedrock 平台。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
注册并创建账户以获取 API 访问权限。
选择 Nova Sonic 模型并配置其参数。
集成 API 到你的应用程序中。
根据需要调用模型进行语音交互和生成。






精选AI产品推荐
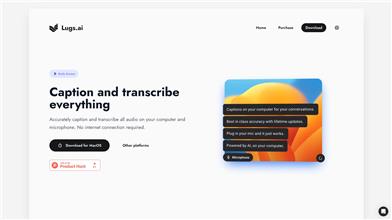
Lugs.ai
Lugs.ai是一款能够在电脑上准确实时生成字幕的插件。无需联网,支持电脑内的所有音频,包括麦克风录音和电脑上的声音。它使用AI技术,可以深度理解对话内容,并根据上下文进行准确的转写和字幕生成。Lugs.ai是由听力受损者开发的,始终以实际使用体验为依据进行不断优化。具备最佳的准确性和持续的更新。
语音识别转写
849.3K
国外精选
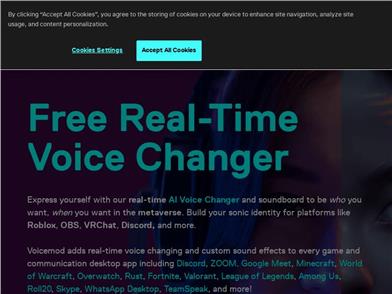
Voicemod
Voicemod是一个免费的实时语音变声器和声音板,可用于Windows和macOS。它可以让您像机器人、恶魔、松鼠、女人、男人或任何您想象的东西一样改变声音。Voicemod可以与所有喜欢的游戏一起使用,并与Elgato Stream Deck、Streamlabs OBS软件、Twitch、TikTok Live Studio、Audacity、Gamecaster或Omegle完美集成。在下次直播时使用实时语音变声器,在几秒钟内为Metaverse和Multiverse平台创建您的Voice Skins和Voice Avatars,或者在使用语音变声器录制视频后进行编辑。立即测试这些声音!
语音识别声音效果
238.2K
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文