

使用场景
在安全监控领域,通过KEEP模型提高视频监控中人脸的识别精度。
在娱乐行业中,用于改善老旧视频资料中的人脸清晰度,提升观看体验。
在社交媒体上,用户可以利用KEEP模型增强自己上传视频的人脸清晰度。
产品特色
编码器和解码器构建的VQGAN生成模型,用于生成高质量的超分辨率图像。
Kalman滤波网络,用于整合Kalman滤波原理,促进时间信息传播并保持稳定的潜在代码先验。
当前帧的观测状态和前一帧的预测状态通过Kalman增益网络进行递归融合,形成当前状态的更准确后验估计。
跨帧注意力(CFA)层,用于进一步促进局部时间一致性,规范信息传播。
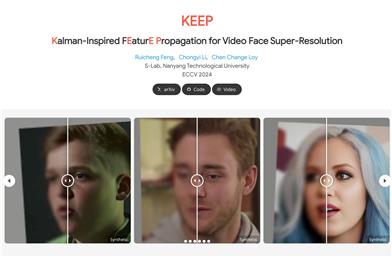
证据累积和增强时间一致性,适用于人脸视频超分辨率。
在ECCV 2024上发表,展示了在视频帧中捕捉人脸细节方面的有效性。
使用教程
1. 访问KEEP模型的官方网页以获取更多信息和代码。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. 阅读相关的研究论文,了解KEEP模型的工作原理和应用场景。
3. 下载并安装必要的软件环境,以运行KEEP模型。
4. 准备需要进行超分辨率处理的视频人脸数据集。
5. 根据文档指导,配置模型参数并加载数据集。
6. 运行KEEP模型,观察并分析超分辨率处理后的结果。
7. 根据需要调整模型参数,以优化超分辨率效果。

%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文