
使用场景
Gemini 1.5 Pro在不同视频长度和子类别中的准确度评分
GPT-4o和GPT-4V在视频分析任务中的表现对比
LLaVA-NeXT-Video模型在不同视频任务中的评分结果
产品特色
提供短、中、长视频的准确度评分
包含6个主要领域和30个子类别的视频类型
全面覆盖视频长度和任务类型
新收集并由人工标注的数据,非现有视频数据集
提供视频类别层级和视频时长及任务类型分布的统计信息
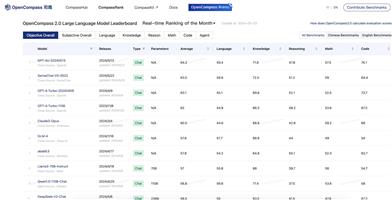
与其他基准测试进行比较,突出Video-MME的独特优势
使用教程
访问Video-MME的官方网站
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
了解不同视频长度和任务类型的评估标准
选择感兴趣的MLLMs模型进行性能测试
提交模型并获取在不同视频子类别中的表现结果
分析结果,与其他模型或基准进行比较
利用评估结果优化和改进MLLMs模型




精选AI产品推荐
Deepeval
DeepEval提供了不同方面的度量来评估LLM对问题的回答,以确保答案是相关的、一致的、无偏见的、非有毒的。这些可以很好地与CI/CD管道集成在一起,允许机器学习工程师快速评估并检查他们改进LLM应用程序时,LLM应用程序的性能是否良好。DeepEval提供了一种Python友好的离线评估方法,确保您的管道准备好投入生产。它就像是“针对您的管道的Pytest”,使生产和评估管道的过程与通过所有测试一样简单直接。
AI模型评测度量
178.3K

Gpteval3d
GPTEval3D是一个开源的3D生成模型评价工具,基于GPT-4V实现了对文本到3D生成模型的自动评测。它可以计算生成模型的ELO分数,并与现有模型进行对比排名。该工具简单易用,支持用户自定义评测数据集,可以充分发挥GPT-4V的评测效果,是研究3D生成任务的有力工具。
AI模型评测GPT
88.0K
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文