首页
AI产品库
模型广场
MCP服务库
AI资讯
首页
全部分类
AI模型评测
Deepmark AI
Deepmark AI
AI模型评测
AI开发平台
#人工智能
#大型语言模型
#可靠性评估
#准确性评估
#成本分析
普通产品
开源
简介 :
Deepmark AI 是一款用于评估大型语言模型(LLM)的基准工具,可在自己的数据上对各种任务特定指标进行评估。它与 GPT-4、Anthropic、GPT-3.5 Turbo、Cohere、AI21 等领先的生成式 AI API 进行预集成。
需求人群 :
Deepmark AI 适用于 Generative AI 构建者,可以根据特定用例的需求,通过迭代评估任务特定指标,识别出最可预测、可靠和经济有效的生成式 AI 模型。
总访问量:
474.6M
占比最多地区:
US(19.34%)
本站浏览量 : 54.1K
打开站点
产品介绍
网站流量
同类开源产品
替代品
使用场景
在自定义数据集上评估不同的生成式 AI 模型
对生成式 AI 模型的准确性进行测试
评估生成式 AI 模型的成本效益
产品特色
可靠性评估
准确性评估
成本分析
相关性评估
延迟评估
失败率评估
流量来源
直接访问
51.61%
外链引荐
33.46%
邮件
0.04%
自然搜索
12.58%
社交媒体
2.19%
展示广告
0.11%
最新流量情况
月访问量
4.92m
平均访问时长
393.01
每次访问页数
6.11
跳出率
36.20%
总流量趋势图
地理流量分布情况
月访问量
4.92m
美国
19.34%
中国
13.25%
印度
9.32%
俄罗斯
4.28%
德国
3.63%
地理流量分布全球图
同类开源产品
Turtle Benchmark
Turtle Benchmark是一款基于'Turtle Soup'游戏的新型、无法作弊的基准测试,专注于评估大型语言模型(LLMs)的逻辑推理和上下文理解能力。它通过消除对背景知识的需求,提供了客观和无偏见的测试结果,具有可量化的结果,并且通过使用真实用户生成的问题,使得模型无法被'游戏化'。
AI模型评测
逻辑推理
Open LLM Leaderboard
Open LLM Leaderboard是一个由Hugging Face提供的空间,旨在展示和比较各种大型语言模型的性能。它为开发者、研究人员和企业提供了一个平台,可以查看不同模型在特定任务上的表现,从而帮助用户选择最适合自己需求的模型。
AI模型评测
性能比较
Mmstar
MMStar是一个旨在评估大型视觉语言模型多模态能力的基准测试集。它包含1500个精心挑选的视觉语言样本,涵盖6个核心能力和18个细分维度。每个样本都经过了人工审查,确保具有视觉依赖性,最小化数据泄露,并需要高级多模态能力来解决。除了传统的准确性指标外,MMStar还提出了两个新的指标来衡量数据泄露和多模态训练的实际性能增益。研究人员可以使用MMStar评估视觉语言模型在多个任务上的多模态能力,并借助新的指标发现模型中存在的潜在问题。
AI模型评测
基准测试
Multi Modal Large Language Models
该工具旨在通过对最新专有和开源MLLMs进行定性研究,从文本、代码、图像和视频四个模态的角度,评估其泛化能力、可信度和因果推理能力,以提高MLLMs的透明度。我们相信这些属性是定义MLLMs可靠性的几个代表性因素,支持各种下游应用。具体而言,我们评估了闭源的GPT-4和Gemini以及6个开源LLMs和MLLMs。总体上,我们评估了230个手动设计的案例,定性结果总结为12个分数(即4个模态乘以3个属性)。总共,我们揭示了14个实证发现,有助于了解专有和开源MLLMs的能力和局限性,以更可靠地支持多模态下游应用。
AI模型评测
评估工具
Gpteval3d
GPTEval3D是一个开源的3D生成模型评价工具,基于GPT-4V实现了对文本到3D生成模型的自动评测。它可以计算生成模型的ELO分数,并与现有模型进行对比排名。该工具简单易用,支持用户自定义评测数据集,可以充分发挥GPT-4V的评测效果,是研究3D生成任务的有力工具。
AI模型评测
GPT
Deepmark AI
Deepmark AI 是一款用于评估大型语言模型(LLM)的基准工具,可在自己的数据上对各种任务特定指标进行评估。它与 GPT-4、Anthropic、GPT-3.5 Turbo、Cohere、AI21 等领先的生成式 AI API 进行预集成。
AI模型评测
大型语言模型
Deepeval
DeepEval提供了不同方面的度量来评估LLM对问题的回答,以确保答案是相关的、一致的、无偏见的、非有毒的。这些可以很好地与CI/CD管道集成在一起,允许机器学习工程师快速评估并检查他们改进LLM应用程序时,LLM应用程序的性能是否良好。DeepEval提供了一种Python友好的离线评估方法,确保您的管道准备好投入生产。它就像是“针对您的管道的Pytest”,使生产和评估管道的过程与通过所有测试一样简单直接。
AI模型评测
度量
替代品
MLE Bench
MLE-bench是由OpenAI推出的一个基准测试,旨在衡量AI代理在机器学习工程方面的表现。该基准测试汇集了75个来自Kaggle的机器学习工程相关竞赛,形成了一套多样化的挑战性任务,测试了训练模型、准备数据集和运行实验等现实世界中的机器学习工程技能。通过Kaggle公开的排行榜数据,为每项竞赛建立了人类基准。使用开源代理框架评估了多个前沿语言模型在该基准上的表现,发现表现最佳的设置——OpenAI的o1-preview配合AIDE框架——在16.9%的竞赛中至少达到了Kaggle铜牌的水平。此外,还研究了AI代理的各种资源扩展形式以及预训练污染的影响。MLE-bench的基准代码已经开源,以促进未来对AI代理机器学习工程能力的理解。
AI模型评测
AI代理
优质新品
SWE Bench Verified
SWE-bench Verified是OpenAI发布的一个经过人工验证的SWE-bench子集,旨在更可靠地评估AI模型解决现实世界软件问题的能力。它通过提供代码库和问题描述,挑战AI生成解决所描述问题的补丁。这个工具的开发是为了提高模型自主完成软件工程任务的能力评估的准确性,是OpenAI准备框架中中等风险级别的关键组成部分。
AI模型评测
软件工程
Turtle Benchmark
Turtle Benchmark是一款基于'Turtle Soup'游戏的新型、无法作弊的基准测试,专注于评估大型语言模型(LLMs)的逻辑推理和上下文理解能力。它通过消除对背景知识的需求,提供了客观和无偏见的测试结果,具有可量化的结果,并且通过使用真实用户生成的问题,使得模型无法被'游戏化'。
AI模型评测
逻辑推理
国外精选
NVIDIA AI Foundry
NVIDIA AI Foundry 是一个平台,旨在帮助企业构建、优化和部署 AI 模型。它提供了一个集成的环境,使企业能够利用 NVIDIA 的先进技术来加速 AI 创新。NVIDIA AI Foundry 的主要优点包括其强大的计算能力、广泛的 AI 模型库以及对企业级应用的支持。通过这个平台,企业可以更快速地开发出适应其特定需求的 AI 解决方案,从而提高效率和竞争力。
AI开发平台
机器学习
扣子专业版
扣子专业版是一款企业级 AI 应用开发平台,旨在帮助用户快速、低门槛地构建个性化的 AI 应用,支持无编程技能的用户使用。该平台拥有 1 万 + 插件的丰富生态,能够构建功能强大的大模型应用,同时支持数据私有化及团队协作,适合各类企业需求。定价灵活,能够满足不同规模的企业使用需求,是推动企业数字化转型的重要工具。
AI开发平台
无代码
国外精选
Scale Leaderboard
Scale Leaderboard是一个专注于AI模型性能评估的平台,提供专家驱动的私有评估数据集,确保评估结果的公正性和无污染。该平台定期更新排行榜,包括新的数据集和模型,营造动态竞争环境。评估由经过严格审查的专家使用特定领域的方法进行,保证评估的高质量和可信度。
AI模型评测
专家评审
Open LLM Leaderboard
Open LLM Leaderboard是一个由Hugging Face提供的空间,旨在展示和比较各种大型语言模型的性能。它为开发者、研究人员和企业提供了一个平台,可以查看不同模型在特定任务上的表现,从而帮助用户选择最适合自己需求的模型。
AI模型评测
性能比较
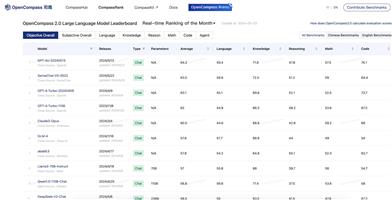
Opencompass 2.0 Large Language Model Leaderboard
OpenCompass 2.0是一个专注于大型语言模型性能评估的平台。它使用多个闭源数据集进行多维度评估,为模型提供整体平均分和专业技能分数。该平台通过实时更新排行榜,帮助开发者和研究人员了解不同模型在语言、知识、推理、数学和编程等方面的性能表现。
AI模型评测
排行榜
Mmstar
MMStar是一个旨在评估大型视觉语言模型多模态能力的基准测试集。它包含1500个精心挑选的视觉语言样本,涵盖6个核心能力和18个细分维度。每个样本都经过了人工审查,确保具有视觉依赖性,最小化数据泄露,并需要高级多模态能力来解决。除了传统的准确性指标外,MMStar还提出了两个新的指标来衡量数据泄露和多模态训练的实际性能增益。研究人员可以使用MMStar评估视觉语言模型在多个任务上的多模态能力,并借助新的指标发现模型中存在的潜在问题。
AI模型评测
基准测试
精选AI产品推荐
Google AI Studio
Google AI Studio是一个基于Vertex AI在Google Cloud上构建和部署AI应用程序的平台。它提供了一个无代码界面,使开发人员、数据科学家和业务分析师能够快速构建、部署和管理AI模型。
AI开发平台
机器学习
1.6M
Vertex AI
Vertex AI提供了构建和部署机器学习模型所需的一体化平台和工具。它具有强大的功能,可以加速自定义模型的训练和部署,并提供预构建的AI API和应用。关键功能包括:集成的工作空间、模型部署与管理、MLOps支持等。可显著提高数据科学家和ML工程师的工作效率。
AI开发平台
机器学习
533.0K
智启未来,您的人工智能解决方案智库
简体中文
© 2025
AIbase
备案号:闽ICP备08105208号-24





%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)