
Comfyui IF MemoAvatar
简介 :
ComfyUI-IF_MemoAvatar是一个基于记忆引导扩散的模型,用于生成表达性的视频。该技术允许用户从单一图像和音频输入创建富有表现力的说话头像视频。这项技术的重要性在于其能够将静态图像转化为动态视频,同时保留图像中人物的面部特征和情感表达,为视频内容创作提供了新的可能性。该模型由Longtao Zheng等人开发,并在arXiv上发布相关论文。
需求人群 :
目标受众包括视频内容创作者、动画师、游戏开发者以及任何需要将静态图像转化为动态视频的用户。该技术特别适合需要在视频制作中实现快速角色生成和表情动画的场景,为用户提供了一个高效且低成本的解决方案。
使用场景
视频游戏开发者使用ComfyUI-IF_MemoAvatar为游戏角色创建动态表情和对话。
电影制作人员利用该技术快速生成电影中角色的对话场景预览。
社交媒体内容创作者使用该工具为他们的静态图像制作动态视频内容,增加互动性和吸引力。
产品特色
从单一图像生成富有表现力的说话视频
音频驱动的面部动画
情感表达转移
高质量视频输出
支持自定义模型文件和参数调整
兼容多种操作系统,包括Linux和Windows
提供详细的安装和使用指南
使用教程
1. 访问GitHub页面并克隆ComfyUI-IF_MemoAvatar仓库到本地。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. 确保环境中已安装Python和必要的依赖库,如PyTorch。
3. 根据项目页面提供的指南安装额外的依赖项,如xformers(如果需要)。
4. 将模型文件下载到指定的目录中,并确保所有文件路径正确。
5. 运行安装脚本,按照提示完成模型的安装和配置。
6. 使用提供的样例脚本进行测试,确保模型能够正常生成视频。
7. 根据需要调整模型参数,以适应不同的输入图像和音频文件。
8. 将生成的视频用于个人或商业项目中。








精选AI产品推荐
国外精选

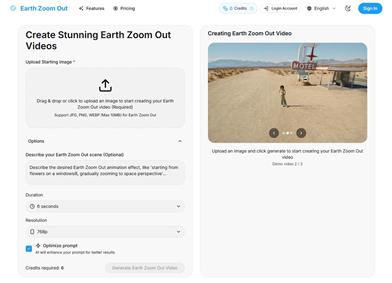
Pika
Pika是一个视频制作平台,用户可以上传自己的创意想法,Pika会自动生成相关的视频。主要功能有:支持多种创意想法转视频,视频效果专业,操作简单易用。平台采用免费试用模式,定位面向创意者和视频爱好者。
视频生成人工智能
18.7M

Deepmind Gemini
Gemini是谷歌DeepMind推出的新一代人工智能系统。它能够进行多模态推理,支持文本、图像、视频、音频和代码之间的无缝交互。Gemini在语言理解、推理、数学、编程等多个领域都超越了之前的状态,成为迄今为止最强大的AI系统之一。它有三个不同规模的版本,可满足从边缘计算到云计算的各种需求。Gemini可以广泛应用于创意设计、写作辅助、问题解答、代码生成等领域。
AI模型多模态
11.4M
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文