
Fasterliveportrait
简介 :
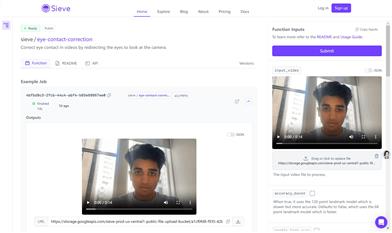
FasterLivePortrait是一个基于深度学习的实时肖像动画化项目。它通过使用TensorRT在RTX 3090 GPU上实现30+ FPS的实时运行速度,包括预处理和后处理,而不仅仅是模型推理速度。该项目还实现了将LivePortrait模型转换为Onnx模型,并在RTX 3090上使用onnxruntime-gpu实现约70ms/帧的推理速度,支持跨平台部署。此外,该项目还支持原生gradio app,速度提升数倍,并支持多张人脸的同时推理。代码结构经过重构,不再依赖PyTorch,所有模型使用onnx或tensorrt进行推理。
需求人群 :
目标受众主要是深度学习开发者、图像处理研究人员和相关领域的专业人士。他们需要在实时环境中对肖像进行动画化处理,或者在跨平台部署中使用深度学习模型。FasterLivePortrait提供了高效的推理速度和灵活的部署方式,适合需要高性能和高兼容性的开发者。
使用场景
使用FasterLivePortrait在视频会议中实时展示动态肖像
将静态肖像照片转换为动态视频,用于社交媒体分享
在游戏或虚拟现实应用中实时生成动态角色肖像
产品特色
使用TensorRT在RTX 3090 GPU上实现30+ FPS的实时运行速度
将LivePortrait模型转换为Onnx模型,支持跨平台部署
支持原生gradio app,提升推理速度并支持多张人脸同时推理
代码结构重构,不再依赖PyTorch,使用onnx或tensorrt进行推理
支持Docker环境,提供可运行的镜像
支持Windows和MacOS集成包,支持一键运行
支持onnxruntime和TensorRT推理,提供详细的安装和使用指南
使用教程
1. 安装Docker并下载FasterLivePortrait的Docker镜像
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. 使用Docker命令运行FasterLivePortrait容器
3. 下载并转换Onnx模型文件,放置在检查点文件夹中
4. 安装并配置onnxruntime-gpu或TensorRT
5. 使用提供的脚本将Onnx模型转换为TensorRT模型
6. 运行app.py启动gradio app,选择onnx或tensorrt模式
7. 访问本地服务器(默认端口9870)并使用app进行实时肖像动画化
















%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文